
机器学习是计算生物学中的一种强大工具,可以分析各种生物医学数据,例如基因组序列和生物成像。但是,当研究人员在计算生物学中使用机器学习时,了解模型行为对于揭示健康和疾病的潜在生物机制仍然至关重要。
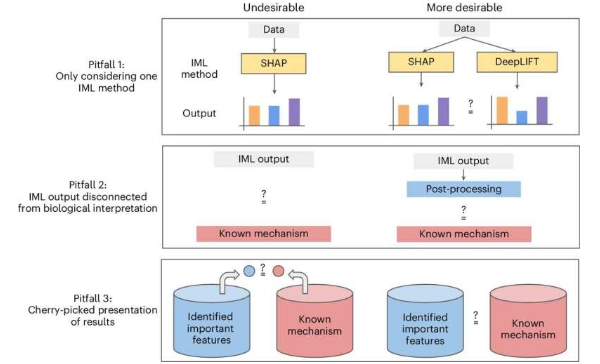
在《自然方法》杂志最近的一篇文章中,卡内基梅隆大学计算机科学学院的研究人员提出了一些指导方针,概述了使用可解释机器学习方法解决计算生物学问题的陷阱和机遇。《观点》杂志的文章《将可解释机器学习应用于计算生物学——陷阱、建议和新发展机遇》刊登在该杂志 8 月的 AI 特刊上。
卡内基梅隆大学机器学习系 (MLD) 副教授 Ameet Talwalkar 表示:“随着机器学习和人工智能工具被应用于越来越重要的问题,可解释的机器学习引起了极大的兴奋。”
“随着这些模型的复杂性不断增加,不仅开发高预测性模型的前景广阔,而且创建工具来帮助最终用户理解这些模型如何以及为何做出某些预测也大有可为。然而,必须承认,可解释的机器学习尚未为这一可解释性问题提供交钥匙解决方案。”